橫空出世的Z-Image簡易出圖(含ComfyUI Desktop安裝說明)
前言
這幾年 AI 影像生成真的很紅,現在很多人其實都是直接用各大公司推出的線上生圖服務,開瀏覽器就能用,真的很方便。不過用久了就會發現,這類服務大多會有題材限制、關鍵字審核,或是每天張數、生成次數的上限,有時候靈感來了卻被限制卡住,蠻可惜的。
然後就想說在自己電腦上就可以跑圖該多好, 可是很多教學一開始就跟你說要高階顯卡、顯存 16GB 起跳,對不少人來說其實直接勸退。其實如果你只是想在自己電腦上玩玩看、做點圖、學習怎麼部署模型,根本不一定要花大錢升級硬體。
當然在自己電腦上弄個模型生圖並不難..但除了硬體需求之外, 最麻煩的就是如何安裝生圖環境及找到合適的模型. 近年來很多開源模型已經做得很不錯, 例如SD1.5, SD XL, Flux.1, 還有最新的Flux.2效果及成果都可以和各大公司的品質媲美. 但安裝的複雜度就難倒一般人, 而且出圖的速度也是慢到一個誇張, 以Flux2來說, 在低階電腦上的生圖, 可能生一張圖要10-20分鐘, 這個對很多人來說已經無法接受.
就在Flux.2發表沒多久, 阿里巴巴也發表了一個開源模型 Z-Image, 就是一個對新手非常友善的選擇,因為模型有經過精練,對硬體需求不高,就算只有入門級的顯卡(例如 RTX2060/3060..等等老顯卡),就可以很快速的出圖,算是近期相當方便的本地 AI 影像模型。
當然有人對於阿里巴巴的背景感到懷疑怕在模型內也會有什麼自我審查機制,不過在實際測試的結果,這種圖也可以生的出來,基本上就不會有什麼問題了.

這篇文章會一步一步帶你完成 Z-Image 的本地部署,從環境準備到實際跑出第一張圖,讓你不用踩太多雷,也能順利把 AI 跑在自己電腦上。
設備
雖然說Z-Image不用太高級的設備, 但還是要有基本的等級, 也不能太差, 顯卡方面至少是nVidia RTX2060/6G 以上才行.. 目前CP值最高應該是5060Ti / 16G, 當然如果有舊的3060/12G 也是可以很順的出圖. 只是愈低階的出圖速度愈慢, 顯存不夠的話..出怪圖的機率還是會出現.
工作環境
我們這次在本地部署Z-Image會使用 ComfyUI 的工作流平台,ComfyUI 是一款目前在 AI 影像生成社群裡非常熱門的 節點式(node-based)介面工具,主要用來建構、編輯和管理 AI 圖像生成的工作流程(workflow)。它跟傳統靠輸入提示詞的生圖介面不太一樣,是把整個生成流程拆成一個個「節點」,讓使用者像拼積木一樣自由組合每個步驟。
ComfyUI 的主要功能重點包括:
節點式流程設計
生成一張圖的每個步驟(像是文字編碼、模型載入、採樣器設定、解碼、儲存輸出等)都被拆成獨立節點,可以任意 拖拉、連線、重組。這種方式讓流程變得非常透明,也便於調整細節。
可視化工作流自由客製化
使用者可以自訂 workflow 並把它 儲存、分享或重用。這對於想要做批量生成、風格統一、加入特定操作(像 ControlNet、Upscaling、Outpainting 等)非常有用。
支援多模型與擴充插件
ComfyUI 可以搭配各種 Stable Diffusion 家族模型、LoRA、ControlNet 或其他自訂節點,讓工作流程具備更高的彈性與強化功能。
本地端執行、無訂閱費用
ComfyUI 是開源、免費的,本地執行,不依賴雲端訂閱服務,生成速度與控制權完全掌握在自己電腦上。
ComfyUI Desktop安裝
ComfyUI有各種安裝或免安裝的方式..但在Windows系統下我覺得最方便的還是直接使用它的Desktop版本, 未來也可以自動升級不用花太時間下載及手動安裝.
在安裝ComfyUI之前, 要先安裝git這個程式, 到 https://git-scm.com/ 網站, 下載Windows版本
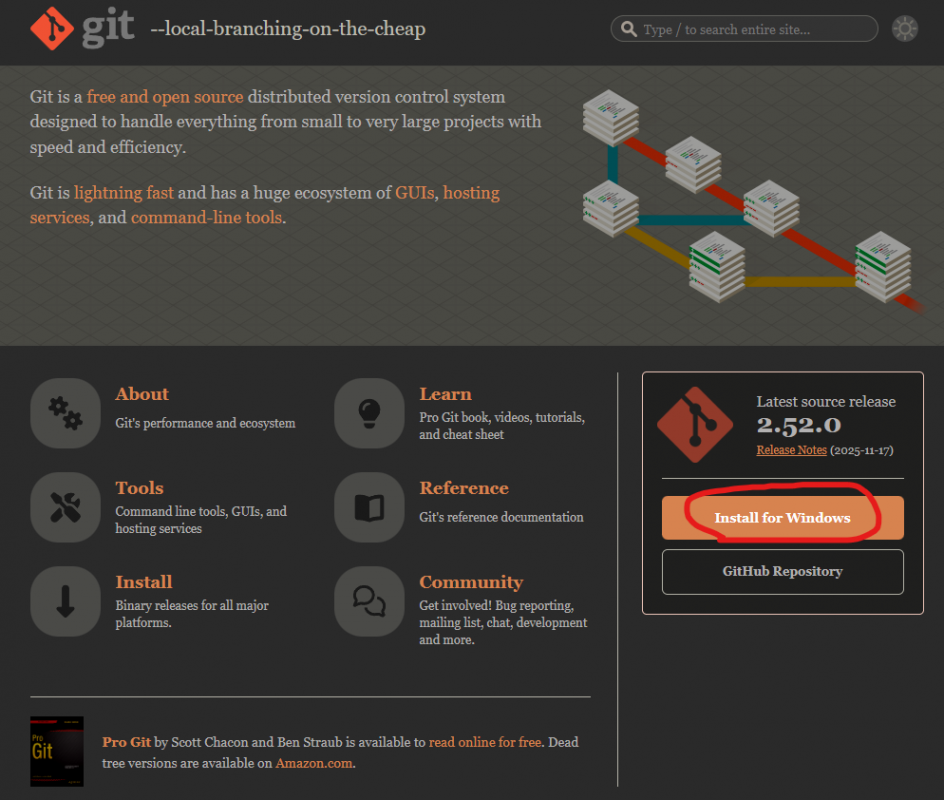
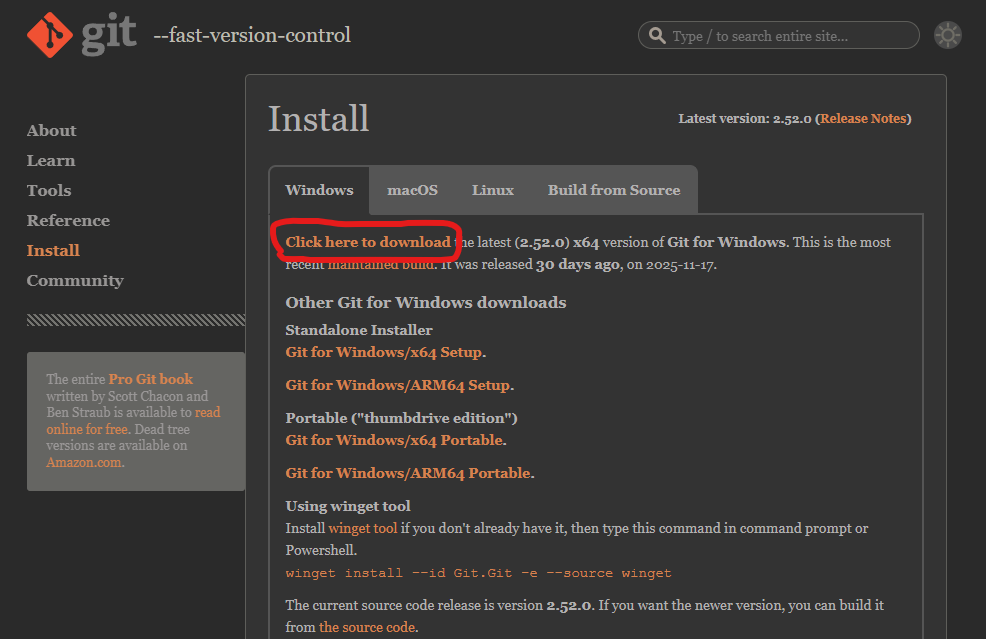
下載後直接安裝(一直按 Next )到結束.
再來就到到Comfy UI官網( https://www.comfy.org/ ) 點選下載ComfyUI鈕

再選擇下載Windows版即可, 下載後點選進行安裝程序

接下來就是一連串安裝過程..其中有2個地方要注意..
首先就是安裝位置, 建議將程式裝在C:\ComfyUI資料夾下.
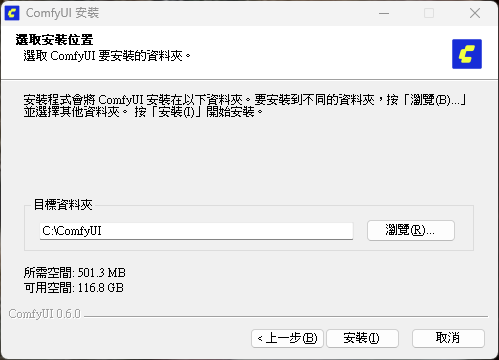
安裝完直接執行..
記得選NVDIA CUDA

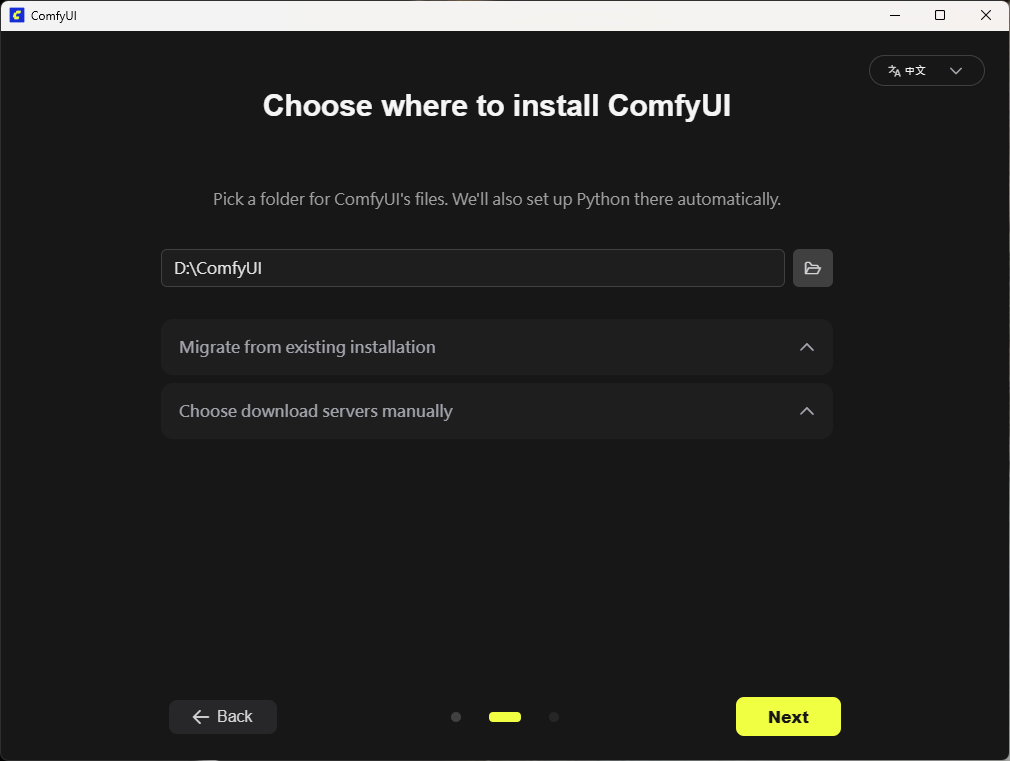
在D:槽開一個 ComfyUI資料夾, 把ComfyUI用的檔案安裝在這裡. 這個是主要的位置, 所有模型及預設出圖都放在這裡(未來會很常用到)
等一段時間之後..看到這個畫面..就代表已經成功安裝了..
接下來就要開始安裝今天的主角Z-Image Turbo模型了.
下載Z-Image Turbo模型
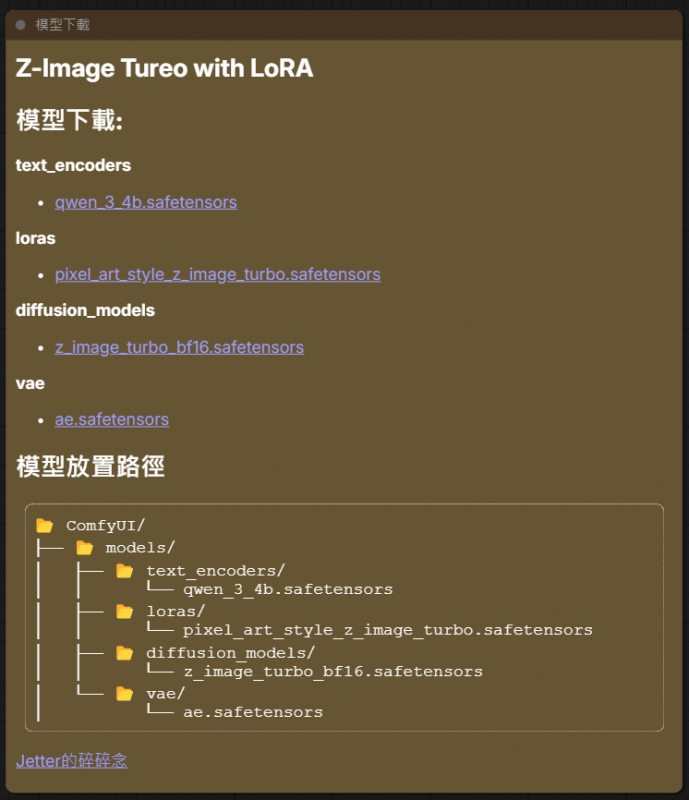
要在ComfyUI使用共有4個檔案要下載, 1個是Z-Image模型, 1個是Qwen3的大語言模型, 它是用來讓Z-Image理解你打的提示詞, 而還有一個vae的圖像理解模型來讓生成的圖像正真實, 最後就是要一個可以用來在ComfyUI裡使用的工作流.
我已經把工作流做好載入時可以自動下載這些模型檔案, 不用一個一個下載而且要手動放到資料夾內
Z-Image Turbo 工作流下載在這裡:Z-image_Turbo.json (請在左邊連結上按右建選另存連結) 把這個json檔下載下來.
再來把這個json檔, 拖到ComfyUI的畫面中(可以先將ComfUI畫面縮小後再把檔案拉進去)
如果是第一次用, 一定不會有剛剛那3個模型檔, 這時..會出現下面的畫面, 說明缺少這幾個檔案, 可以直接一個一個點 下載, 它就會自動把模型檔下載到應該存放的位置.
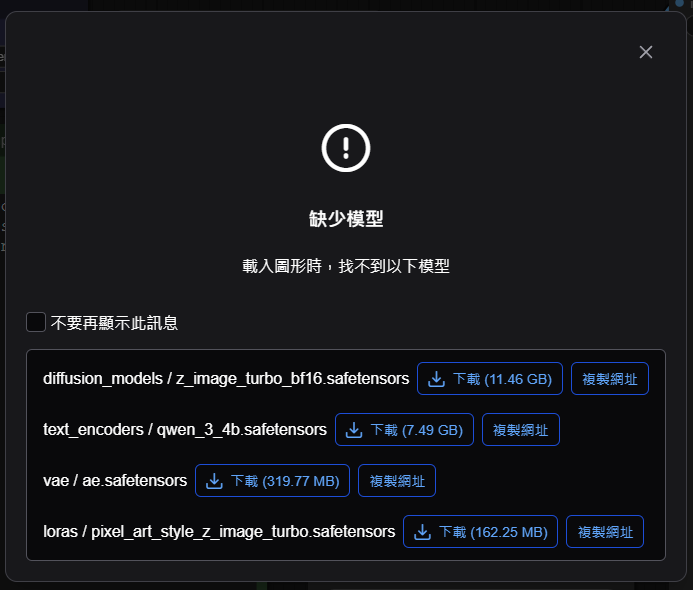
等下載完後, 建議關掉ComfyUI再重新進去一次.. 進入時..就會看到剛剛拉進去的工作流已經在畫面中了
如果忘了在這個畫面下載.. 也沒關係.. 工作流中我有放一個下載網址和放置的資料夾..直接點就可以下載了..
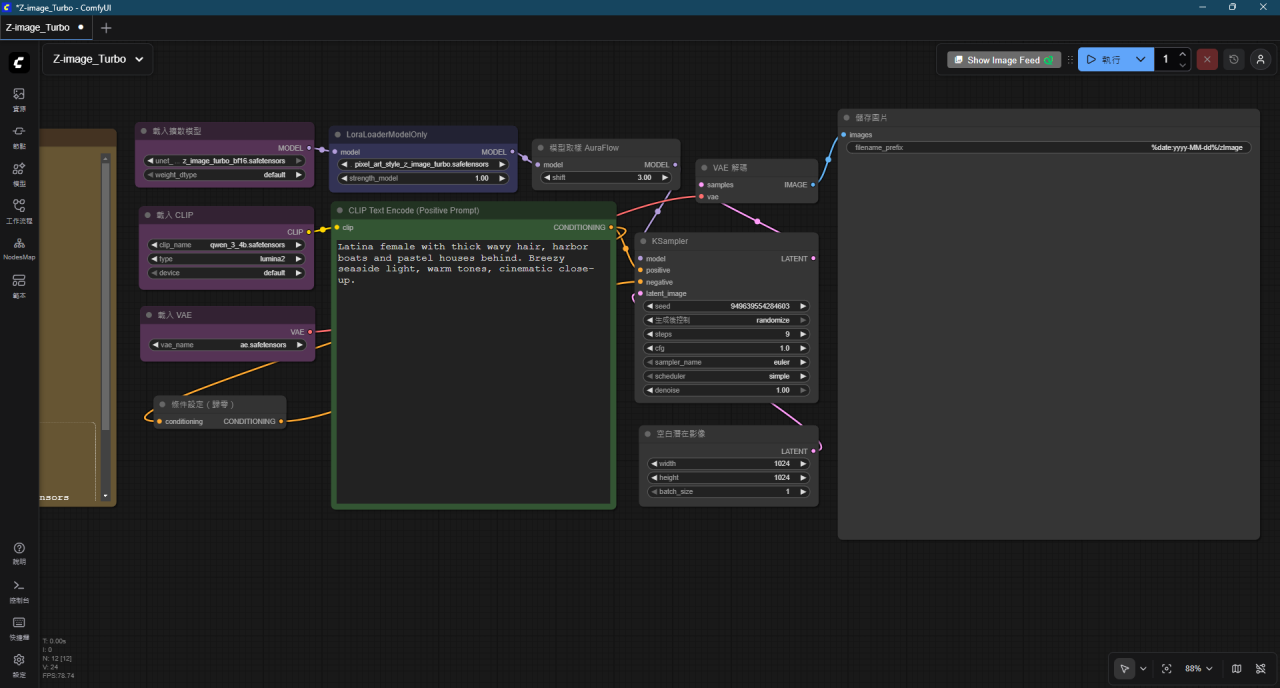
這時可以直接按一下.. 執行 鈕..第一次要載入模型會比較慢..再來就可以直接出圖囉..
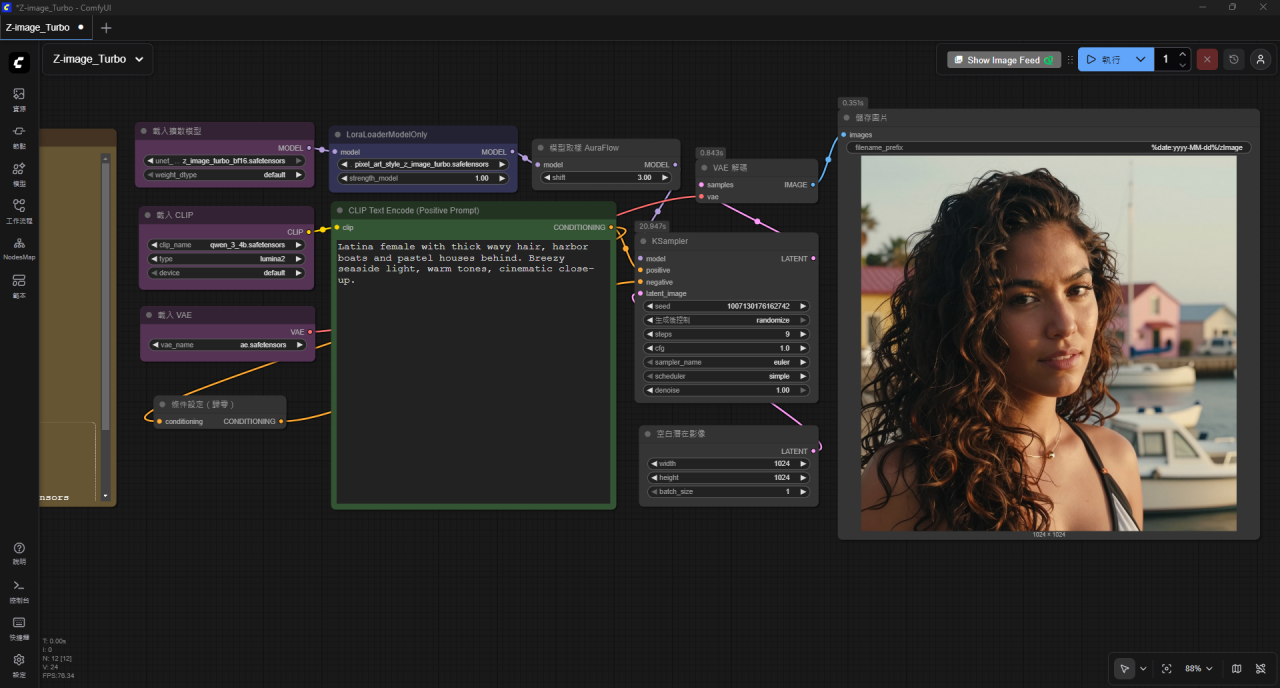
這時可以直接在中間綠色方塊輸入提示詞(中英文都可以), 就可以生成想要的圖囉.
加入LoRA
簡單來說:LoRA是訓練特定概念或風格的模組,可以擴展模型能描繪的概念範圍,例如畫特定鳥類、老婆(waifus)或模仿名家畫風。
因為訓練LoRA就不是一般配備可以達成, 但有很多大大已經幫我們訓練了不少LoRA可以套用, 可以到C站(https://civitai.com/) 搜尋並下載即可.
搜尋方式
進入C站後..點一下Models
因為C站有很多各種模型的資訊, 所以最好到同一行的最右方點一下過濾器Filters
點開過濾器後..選LoRA及Z Image Turbo
這樣就可以瀏覽專為Z Image訓練的LoRA風格了.
看到想要的風格, 例如這個
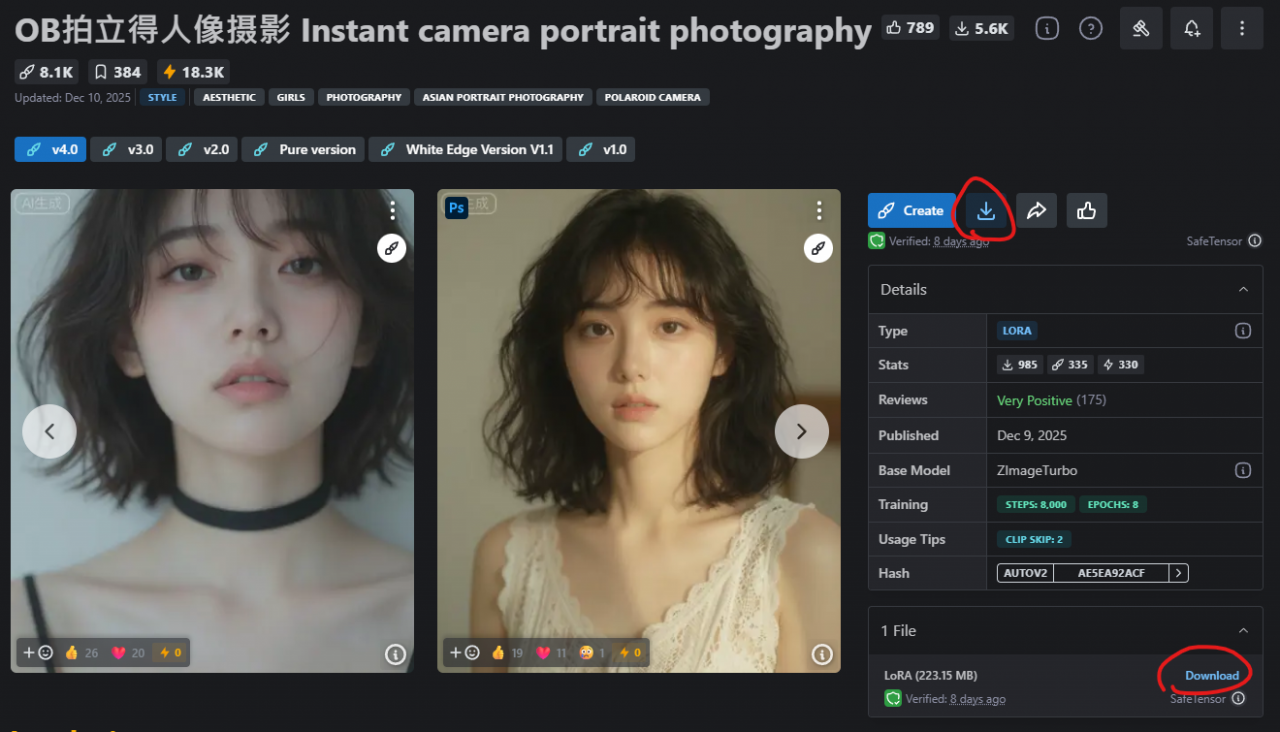
把下載後的檔案(以這個為例, 檔名為: OB拍立得人像摄影Instant camera portrait photography V4.0.safetensors ), 移到 D:\ComfyUI\models\loras 資料夾下(上面安裝教學時的第二個安裝位置就是這裡)
把檔案放入後, 回到ComfyUI中, 按一下鍵盤的 “R” 鍵..它會重新讀取各節點的內容..這樣剛剛放進去的檔案才能使用.
LoRA放了之後..到LoRA選擇器中..選擇剛剛這個LoRA
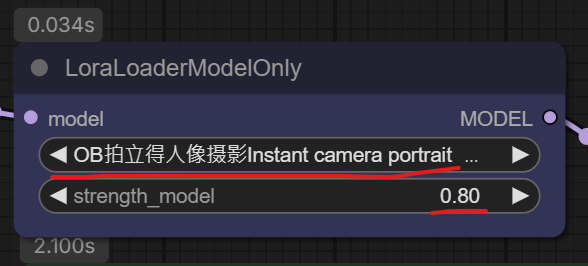
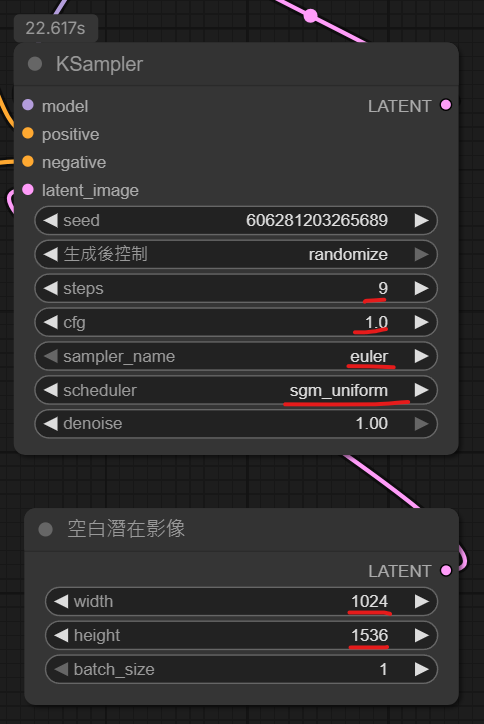
也依作者說明..將這些參數調整了一下..

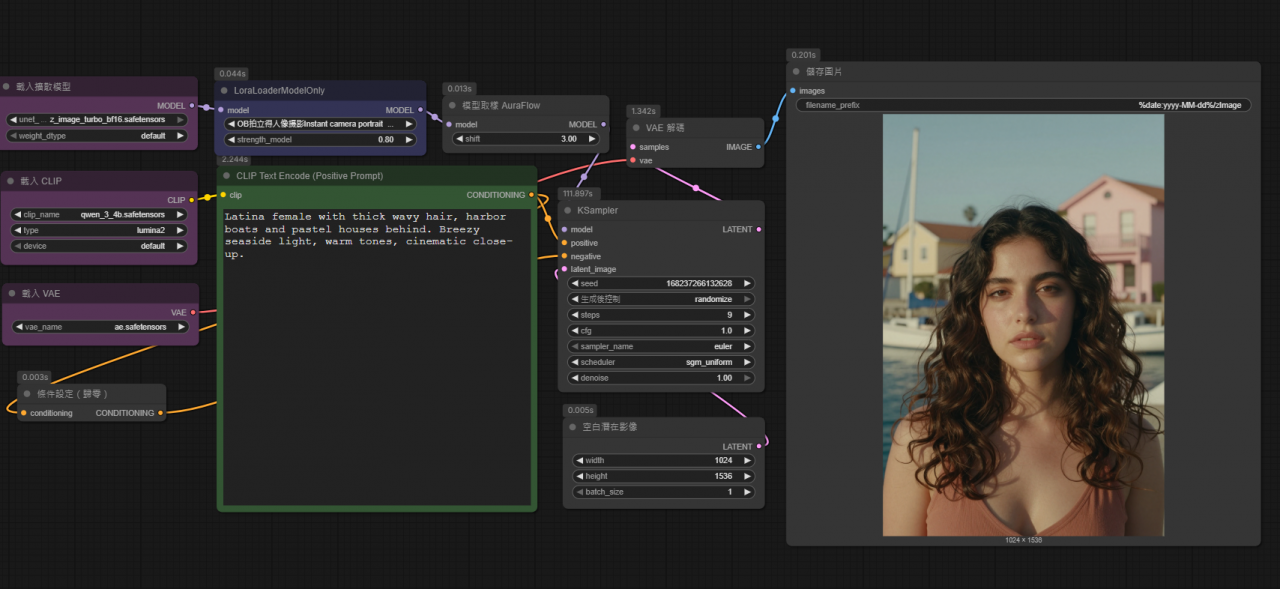
然後直接再跑一次..就會發現相片的風格已經改變了.
當然如果想要一次套用多個風格, 那麼就把LoRA節點複製後再串起來即可.
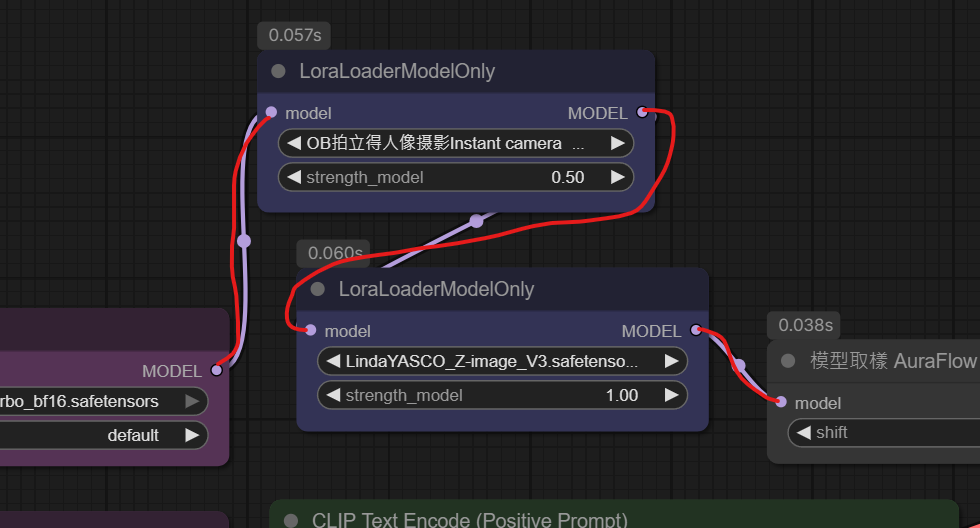
如果LoRA疊加有時要調整一下權重(例如剛剛的拍立得風格作者有說如何和別的LoRA一起使用, 權重設0.5即可)
疊加LoRA的效果(它是拍立得風格疊加我訓練的LindaYASCO人物), LindaYASCO也有公佈在C站, 可以自行下載使用.
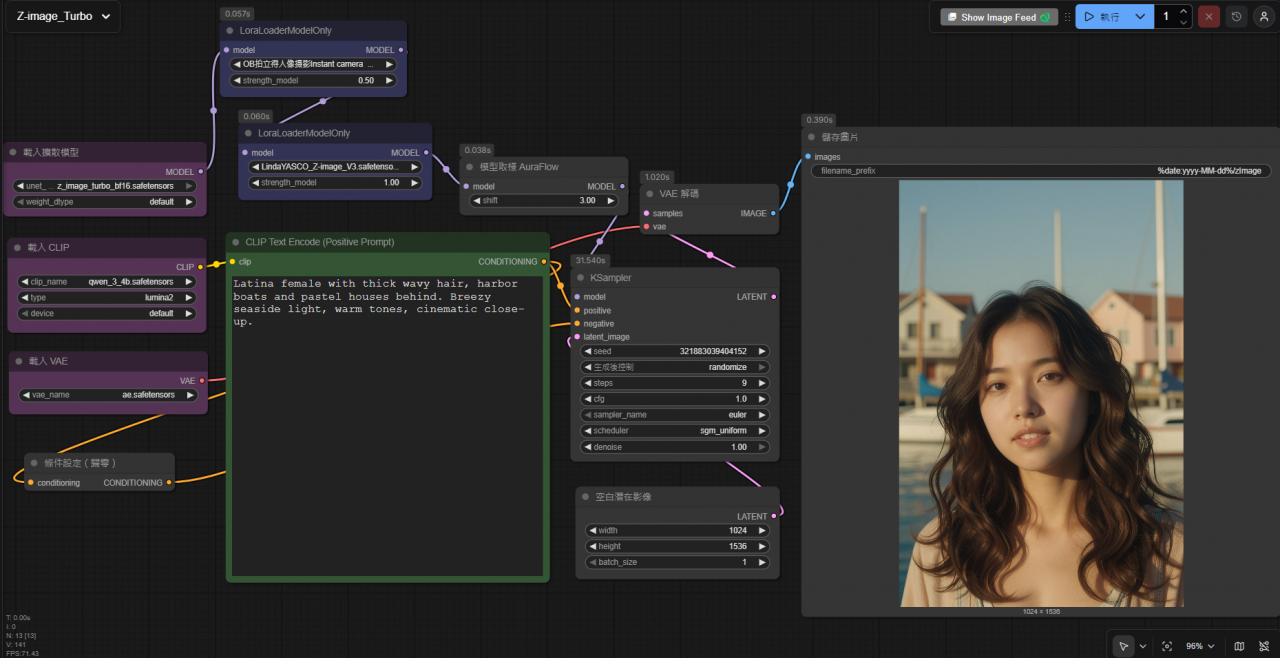
以上就是Z-Image Turbo 加上 LoRA的說明.. 希望大家都可以生出喜歡的圖片..
最後附上幾張在範例生的圖, 圖片儲放的位置在 D:\ComfyUI\outputs\生圖的日期\ (如果你沒修改我的預設位置的話)







